
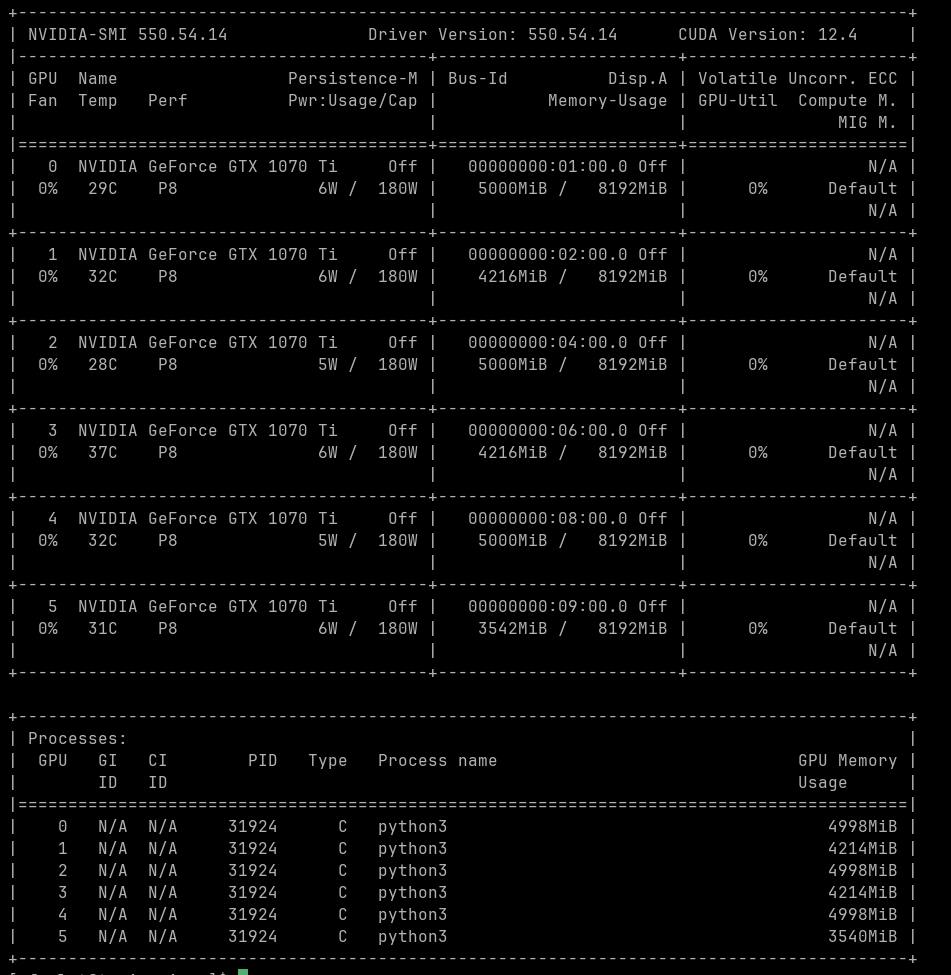
Au taff, on vient de recycler un vieux coucou avec 6 cartes GTX 1070 Ti, des trucs de 2017 dits "désuets" par #Nvidia.
#llamacpp démarre un #Mixtral8x7b réparti sur les cartes... Et ça va plus vite que ChatGPT.
Une interface codée en #gradio de 30 lignes.
Si ça c'est pas rentabiliser !
PS: on va virer CUDA et utiliser #Vulkan d'ici peu
{kind=link}
Suivre
Mode RPC testé. C'est super efficace, le modèle se répartit super bien sur les cartes graphiques du réseau.
C'est lent à charger par contre (au démarrage), mais les inférences sont très rapides, presque comme si on faisait tout tourner localement.
Donc, si vous avez plusieurs PC/Mac et que vous voulez charger des gros modèles, c'est clairement bien foutu.
#llamacpp est tout simplement épatant.
